Ars Electronica 2013 – Quotidian Record
I find the syntax of CrossApply more elegant and easier to use than UnPivot. See for your self in this sample below. Let me know which one you prefer.
/*
Proof of concept for pivoting table with cross apply.
Autjor: Tim Bartel 2015.09.23
*/
-- Let's create simple table of employee sales records
create table sales (
recordID int IDENTITY(1,1) NOT NULL,
storeID int,
employeeID int,
promo1 decimal(16,2),
promo2 decimal(16,2),
promo3 decimal(16,2),
promo4 decimal(16,2),
promo5 decimal(16,2),
aprove1 varchar(3),
aprove2 varchar(3),
aprove3 varchar(3),
aprove4 varchar(3),
aprove5 varchar(3),
date1 date,
date2 date,
date3 date,
date4 date,
date5 date
)
Now let’s add some data:
insert into sales (storeID, employeeID, promo1, promo2, promo3, promo4, promo5, aprove1, aprove2, aprove3, aprove4, aprove5, date1, date2, date3, date4, date5)
values ('251', '12', '350.00', '275.00', '110.00', '50.50', '1111.11', 'AA', 'RJ', 'AA', 'AA', 'TD', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-07-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('251', '12', '750.00', '550.00', '330.00', '151.00', '1111.11', 'RN', 'RJ', 'AA', 'RN', 'TD', cast('2015-01-28' as date), cast('2015-03-15' as date), cast('2015-06-29' as date), cast('2015-08-03' as date), cast('2015-09-22' as date)),
('251', '12', '350.00', '275.00', '110.00', '50.50', '1000.00', 'AA', 'RJ', 'AA', 'AA', 'TD', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-07-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('251', '12', '350.00', '275.00', '110.00', '850.50', '11.11', 'AA', 'RJ', 'AA', 'AA', 'TD', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-06-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('190', '12', '350.00', '275.00', '110.00', '50.50', '100.00', 'AA', 'RJ', 'AA', 'AA', 'TD', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-05-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('250', '10', '350.00', '275.00', '110.00', '50.50', '1111.11', 'SA', 'RJ', 'SA', 'SA', 'RJ', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-07-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('250', '10', '750.00', '550.00', '330.00', '151.00', '1111.11', 'RN', 'RJ', 'AA', 'RN', 'RJ', cast('2015-01-28' as date), cast('2015-03-15' as date), cast('2015-06-29' as date), cast('2015-08-03' as date), cast('2015-09-22' as date)),
('250', '10', '350.00', '275.00', '110.00', '50.50', '1000.00', 'SA', 'RJ', 'SA', 'SA', 'RJ', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-07-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('250', '10', '350.00', '275.00', '110.00', '850.50', '11.11', 'AA', 'RJ', 'AA', 'AA', 'TD', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-06-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('251', '10', '350.00', '275.00', '110.00', '50.50', '100.00', 'AA', 'RJ', 'AA', 'AA', 'TD', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-05-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('33', '34', '350.00', '275.00', '110.00', '50.50', '1111.11', 'SA', 'RJ', 'SA', 'SA', 'RJ', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-07-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('33', '15', '750.00', '550.00', '330.00', '151.00', '1111.11', 'RN', 'RJ', 'AA', 'RN', 'RJ', cast('2015-01-28' as date), cast('2015-03-15' as date), cast('2015-06-29' as date), cast('2015-08-03' as date), cast('2015-09-22' as date)),
('33', '34', '350.00', '275.00', '110.00', '50.50', '1000.00', 'SA', 'RJ', 'SA', 'SA', 'RJ', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-07-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('91', '13', '350.00', '275.00', '110.00', '850.50', '11.11', 'AA', 'RJ', 'AA', 'AA', 'TD', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-06-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date)),
('91', '13', '350.00', '275.00', '110.00', '50.50', '100.00', 'YY', 'OT', 'PB', 'YY', 'VW', cast('2015-01-25' as date), cast('2015-05-05' as date), cast('2015-05-19' as date), cast('2015-09-22' as date), cast('2015-09-22' as date))
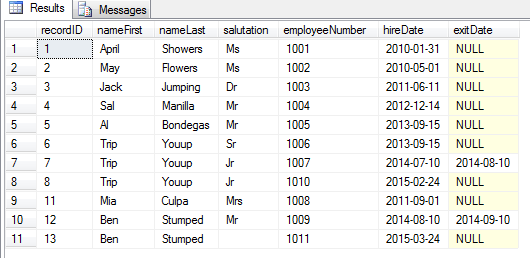
Let’s look at how this data ia arranged, how it is pivoted from vertical to horizontal
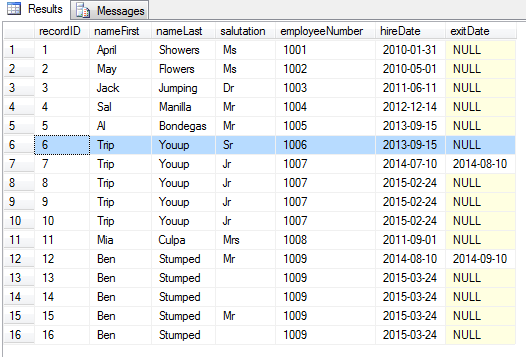
select * from sales
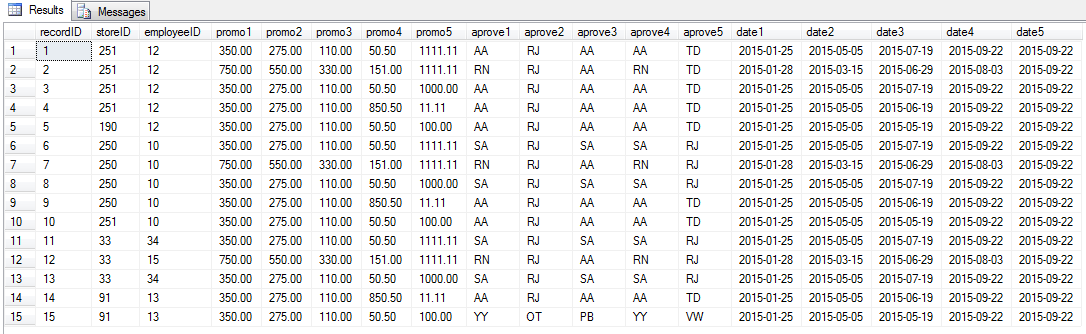
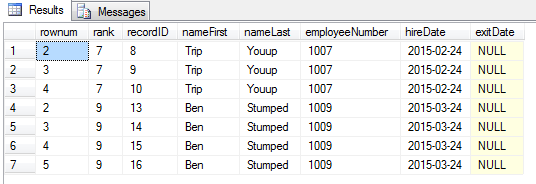
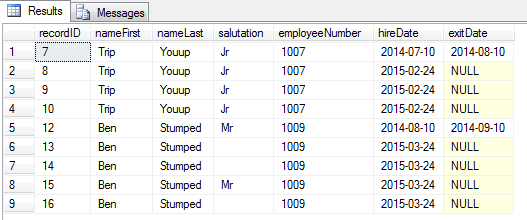
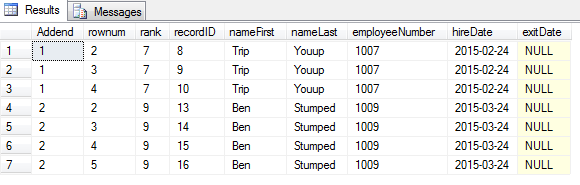
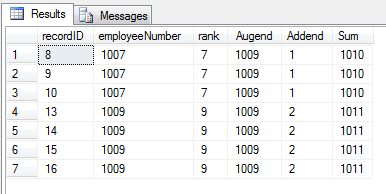
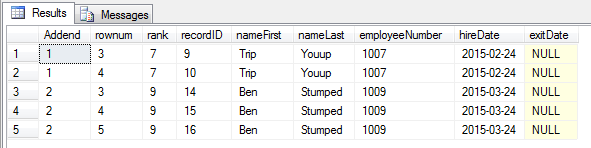
This is not very conducive to getting total sales by employee or by store. Not easy to order by promo, approval, or date. We need result like this pivoted table below (total is 75 lines, image samples at 29 lines):
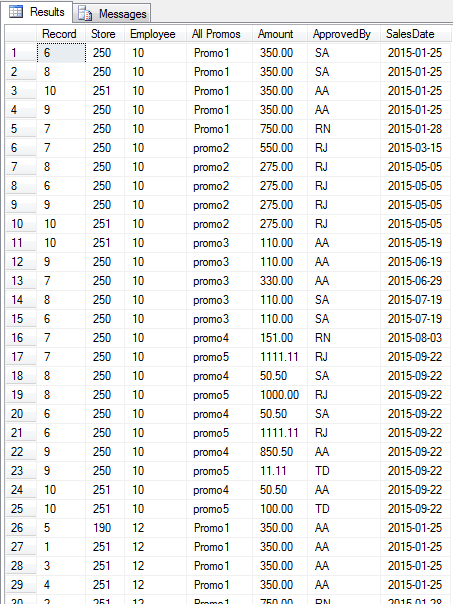
Compare the next two queries, each of which produce the same table as pictured above, and see which one is more elegant and concise. First, using UNPIVOT:
-- Let's unpivot using Unpivot
SELECT RecordID Record, StoreID Store, employeeID Employee,
Promos 'All Promos',
AllPromos Amount, AllApprovals ApprovedBy, AllDates SalesDate
--, SubID=ROW_NUMBER() OVER (PARTITION BY StoreID ORDER BY AllPromos)
FROM (
SELECT RecordID, StoreID, EmployeeID, promo1 , promo2, promo3, promo4, promo5, aprove1, aprove2, aprove3, aprove4, aprove5, date1, date2, date3, date4, date5
FROM sales) Promos
UNPIVOT ( AllPromos FOR Promos IN (promo1 , promo2, promo3, promo4, promo5)) SortPromos
UNPIVOT ( AllApprovals FOR Approvals IN (aprove1, aprove2, aprove3, aprove4, aprove5)) SortApprovals
UNPIVOT ( AllDates FOR Dates IN (date1, date2, date3, date4, date5)) SortDates
where RIGHT(Promos, 1) = RIGHT(Approvals, 1) and RIGHT(Approvals, 1) = RIGHT(Dates,1) order by employeeID, AllDates
And now using CROSS APPLY:
-- Let's unpivot using cross apply
select * from (
SELECT Record, Store, Employee, Promos as 'All Promos', Amount, ApprovedBy, SalesDate -- you can name these whatever you want but they have to match below. You can use an alias here but not below
FROM sales
CROSS APPLY (VALUES
(RecordID, storeID, employeeID, 'Promo1', promo1, aprove1, date1),
(RecordID, storeID, employeeID, 'promo2', promo2, aprove2, date2),
(RecordID, storeID, employeeID, 'promo3', promo3, aprove3, date3),
(RecordID, storeID, employeeID, 'promo4', promo4, aprove4, date4),
(RecordID, storeID, employeeID, 'promo5', promo5, aprove5, date5)
) SalesByPromo -- you can add a where clause but not an order by clause
(Record, Store, Employee, Promos, Amount, ApprovedBy, SalesDate) -- these have to match above
) SalesByEmployee order by employee, SalesDate
It really doesn’t matter to me that CROSS APPLY has a few more lines, because it just makes more sense, has greater parallelism and symmetry. Plus you only need to write CROSS APPLY once where as UNPIVOT has to be written for each column set. And you only name the one CROSS APPLY derived table whereas you have to name each UNPIVOT. Considering that there is an understandably strong push for code that is as human readable as possible, my vote is for CROSS APPLY every time. As for performance, execution time differences are negligible but CROSS APPLY pulls ahead as you tack on secondary and tertiary UNPIVOT instances. CROSS APPLY is the clear winner for me. Let me know what you think.